第 2 章 结构化查询语言
本章的数据库查询操作大部分是在 Northwind 示例数据库上完成的。
下面是 Northwind 数据库的安装步骤:
- 在 linux 终端执行下面的命令,下载
northwind.sql脚本文件 wget http://sample.wangding.co/dbms/northwind.sql- 执行下面的命令,执行
northwind.sql脚本文件 mysql < northwind.sql- 执行下面的命令,验证示例数据库是否安装成功
mysql -e "show databases;"
基础查询
投影操作
要求:
- 在
dbms-demo目录下,创建02-sql文件夹 - 在 MySQL Shell(或 MySQL Workbench)中完成下面的查询操作
- 下面的所有查询都在上面导入的
northwind示例数据库上完成 - 查询常量值
hello world - 在
employees表中,查询first_name字段 - 在
employees表中,查询first_name,last_name和salary字段 - 在
employees表中,查询所有字段 - 查询表达式,计算半径为 4 的圆的面积
- 查询函数,获得当前 MySQL 服务器的版本
- 浏览 MySQL 手册,浏览 MySQL 内置函数的分类,找到获取 MySQL 版本函数的分类
- 查询函数,获得当前时间
- 查询函数,获得当前登录的用户
- 查询表达式,使用幂函数,计算半径为 4 的圆的面积,$$S=\pi r^2$$
- 使用别名修改前面的查询,提高查询结果的可读性
- 在
employees表中,查询employee_id,last_name和annual_salary字段 - 在
employees表中,查询 fullname 字段,fullname = firstname + ' ' + lastname - 类似上一条查询,要求查询结果显示的字段为:
employee fullname - 在
employees表中,查询first_name,last_name,job_id和commission_pct列,各个列之间用逗号连接,字段显示为 output - 查询
departments表的结构 - 在
departments表中,查询所有字段 - 在
employees表中,查询所有不同的部门编号 - 在
employees表中,查询所有不同的工作编号 - 将上面的 SQL 代码放到
02-sql目录下的01-project.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
选择操作
要求:
- 如果没有特别说明,下面的查询都在 northwind 库的 employees 表中操作
- 查询工资大于 12000 的员工信息
- 查询部门编号不等于 90 的员工 last_name 和部门编号
- 查询工资在 10000 到 20000 之间的员工 last_name、工资以及提成
- 查询部门编号不是在 90 到 110 之间,或者工资高于 15000 的员工信息
- 查询员工
lastname中包含字符a的员工信息 - 查询员工
lastname中第三个字符为n,第五个字符为l的员工 last_name 和工资 - 查询员工 job_id 中第三个字符为 _ 的员工 last_name 和 job_id
- 查询员工编号在 100 到 120 之间的员工信息
- 查询工种编号在 it_prog、ad_vp、ad_pres 中的员工 last_name 和工种编号
- 查询没有提成的员工 last_name 和提成
- 查询工资为 12000 的员工 lastname 和工资
- 将上面的 SQL 代码放到
02-sql目录下的02-select.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
排序/分页
要求:
- 如果没有特别说明,下面的查询都在 northwind 库的 employees 表中操作
- 查询所有信息,按工资降序排序
- 查询部门编号大于等于 90 的员工信息,并按员工编号降序排序
- 查询所有员工信息,按年薪降序排序
- 查询所有员工信息,按年薪升序排序
- 查询员工名字 first_name 和名字长度,并且按名字的长度降序排序
- 查询所有员工信息,先按工资降序,再按 employee_id 升序排序
- 查询员工名字,部门编号和年薪,按年薪降序并按姓名升序排序
- 查询工资不在 8000 到 17000 的员工的名字和工资,按工资降序排序
- 查询邮箱中包含
e的员工信息,并先按邮箱的长度降序,再按部门号升序排序 - 查询前五条员工信息
- 查询第 11 条 ~ 第 25 条
- 查询有提成,且工资最高的前 10 位员工信息
- 将上面的 SQL 代码放到
02-sql目录下的03-sort-page.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
内置函数
要求:
- 如果没有特别说明,下面的查询都在 northwind 库的 employees 表中操作
- 查询员工编号、名字、工资、以及工资提高百分之 20% 后的结果 new_salary
- 将员工的姓氏按首字母升序排序,并查询姓氏和姓氏的长度 length
- 查询员工编号、名字,薪水,作为一个列输出(逗号分割),别名为 output
- 查询员工编号、工作的年数 work_years(保留小数点后 1 位)、工作的天数 work_days,并按工作年数的降序排序
- 查询员工名字、入职时间(格式:MM-DD/YYYY)、部门编号、提成,并同时满足以下条件:
- 入职时间在 1997 年之后
- 部门编号是 80 或 90 或 110
- 提成不为空
- 查询入职超过 10000 天的员工名字和入职时间
- 查询 dream,
dream = <first_name> earns <salary> monthly but wants <salary>*3,salary 不要小数部分 - 查询员工的名字和提成信息 commission,提成信息的内容如下
- commission_pct 不是 null, 显示为
有提成,否则,显示为无提成
- commission_pct 不是 null, 显示为
- 查询员工的工资、部分编号和 new_salary,其中 new_salary 的计算如下
- 部门编号如果是 30,new_salary 为 1.1 倍工资
- 部门编号如果是 40,new_salary 为 1.2 倍工资
- 部门编号如果是 50,new_salary 为 1.3 倍工资
- 其他部门,new_salary 为原工资
- 查询员工名字、工种以及工种的等级,其中工种的等级如下:
- 如果 job_id 为 AD_PRES,grade 为 A 级
- 如果 job_id 为 ST_MAN,grade 为 B 级
- 如果 job_id 为 IT_PROG,grade 为 C 级
- 如果 job_id 为 SA_REP,grade 为 D 级
- 如果 job_id 为 ST_CLERK,grade 为 E 级
- 其他工种 grade 为 F 级
- 查询员工的名字、工资以及工资级别 grade,grade 计算如下:
- 如果工资大于 20000,grade 为 A 级
- 如果工资大于 15000,grade 为 B 级
- 如果工资大于 10000,grade 为 C 级
- 否则,grade 为 D 级
- 查询员工工资的最大值、最小值、平均值、总和和数量
- 查询最早入职时间、最近入职时间以及两者相差的天数 diff
- 查询部门编号为 90 的员工人数
- 将上面的 SQL 代码放到
02-sql目录下的04-buildin-functions.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
集合运算
要求:
- 下载
set.sql脚本文件,wget http://sample.wangding.co/dbms/set.sql - 安装
set_demo示例数据库,具体操作参考安装 northwind 数据库 - 对
set_demo数据库的set_a和set_b两个表做并运算,观察查询结果 - 用
union关键字,在employees表中,查询部门编号大于 90 或邮箱包含 a 的员工信息 - 交和差集合运算只在 MySQL 8.0.31 版本以上支持
- 对
set_demo数据库的set_a和set_b两个表做交运算,观察查询结果 - 对
set_demo数据库的set_a和set_b两个表做差运算,观察查询结果 - 对
set_demo数据库的set_a和set_c两个表做积运算,观察查询结果 - 将上面的 SQL 代码放到
02-sql目录下的05-set.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
高级查询
分组查询
要求:
- 如果没有特别说明,下面的查询都在 northwind 库的 employees 表中操作
- 查询员工最高工资和最低工资的差距 diff
- 查询工种编号和该工种的员工人数 num
- 查询工种编号和该工种的平均工资 average_salary(去掉小数部分)
- 在 departments 表中,查询位置编号和该位置的部门个数 num
- 查询部门编号和该部分员工邮箱中包含 a 字符的最高工资
- 查询管理者编号,以及该领导手下有提成的员工的平均工资(去掉小数)average_salary
- 查询部门编号和该部门的员工人数 num,只要 num>5 的数据
- 查询工种编号和该工种有提成的员工的平均工资 average_salary,只要 average_salary>12000 的数据
- 查询管理者编号和该领导手下员工的最低工资 min_salary,只要 min_salary>5000 的数据
- 查询管理者编号和该领导手下员工的最低工资 min_salary,只要 min_salary >= 6000 的数据,没有管理者的员工不计算在内
- 查询工种编号,以及该工种下员工工资的最大值,最小值,平均值,总和,并按工种编号降序排序
- 查询工种编号和该工种有提成的员工的最高工资 max_salary,只要 max_salary>6000 的数据,对结果按 max_salary 升序排序
- 查询部门编号、该部门员工人数 num 和该部门工资平均值 average_salary,并按平均工资降序排序
- 查询部门编号、工种编号和该部门和工种的员工的最低工资 min_salary,并按最低工资降序排序
- 将上面的 SQL 代码放到
02-sql目录下的06-group.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
多表查询
要求:
- 下载
join.sql脚本文件,wget http://sample.wangding.co/dbms/join.sql join_demo示例数据库安装的方式,参考安装 northwind 数据库join_demo示例数据库的三个表,内容如下:
tb_a tb_b tb_c+------+------+------+ +------+------+ +------+------+------+| c1 | c2 | c3 | | c1 | c2 | | c1 | c4 | c3 |+------+------+------+ +------+------+ +------+------+------+| a | x1 | 1 | | 1 | y1 | | 1 | x1 | a || b | x2 | 2 | | 2 | y2 | | 2 | x2 | b || c | x3 | 3 | | 4 | y3 | | 3 | x3 | c |+------+------+------+ +------+------+ +------+------+------+- 在
tb_a和tb_b表上做内连接、左外连接、右外连接、全外连接、笛卡尔积和交叉连接 - 在
tb_b和tb_c表上做自然连接 - 参考下图,在
tb_a和tb_b表上完成七种连接操作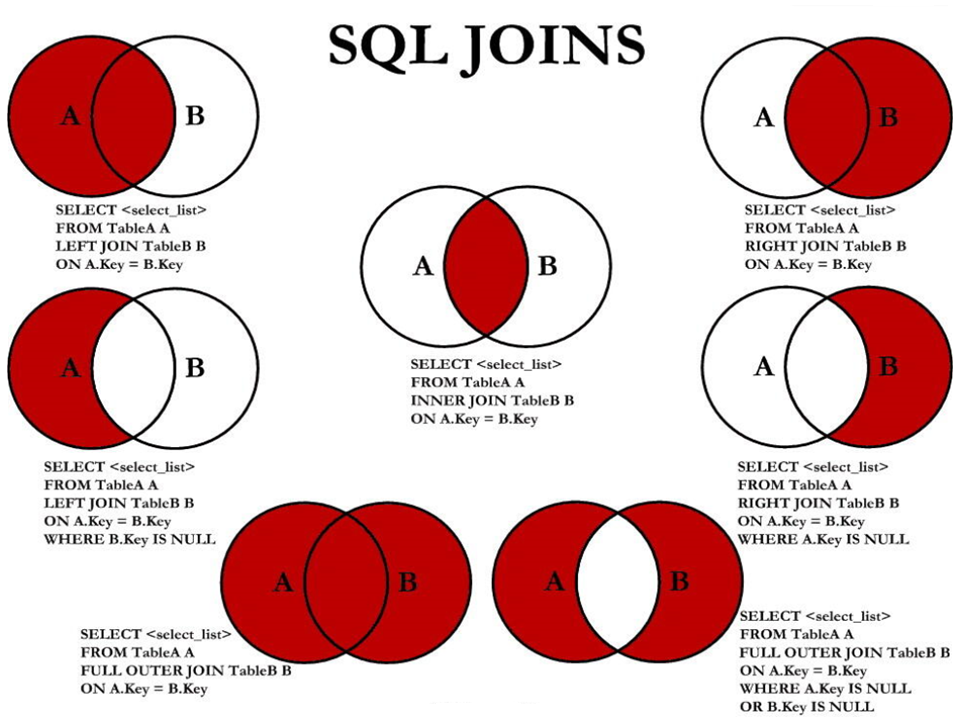
- 下面的查询可能涉及到 employees 表,departments 表和 locations 表,他们之间的关系见下图

- 查询员工名字和所在部门的名称
- 查询员工名字、工种编号和工种名称
- 查询有提成员工的员工名字、部门名称和提成
- 查询所在城市名中第二个字符为 o 的部门名称和城市名
- 查询城市名称和该城市拥有的部门数量,过滤没有部门的城市
- 查询有提成的部门,部门名称、部门的领导编号和部门的最低工资 min_salary
- 查询每个工种的工种名称和员工人数,并且按员工人数降序排序
- 查询员工名字、部门名称和所在的城市,并按部门名称降序排序
- 查询员工的工资和工资级别
- 查询员工编号、员工名字、上司编号和名字
- 查询 90 号部门员工的工种编号和位置编号
- 查询有提成的员工,员工名字、部门名称、位置编号和城市
- 查询在 toronto 市工作的员工,员工名字、工种编号、部门编号和部门名称
- 查询每个部门的部门名称、工种名称、该工种的最低工资
- 查询拥有部门数量大于 2 的国家,国家编号和部门数量
- 查询名为 Lisa 的员工,员工编号、其上司编号和名字
- 查询没有部门的城市
- 查询任职部门名为 sal 和 it 的员工信息
- 查询名字中包含 e 的员工,其名字和工种名称
- 查询拥有部门数量大于 3 的城市,城市名和部门数量
- 查询员工人数大于 10 的部门,部门名称和员工人数,并按人数降序排序
- 查询员工名字、部门名称、工种名称,并按部门名称降序排序
- 查询员工的工资和工资级别
- 查询工资级别和该级别的员工人数,不包括人数小于 20 的工资级别
- 查询所有员工的名字和所属部门的名称
- 查询所有部门的名称以及该部门的平均工资 average_salary (不要小数部分),并按平均工资降序排序
- 将上面的 SQL 代码放到
02-sql目录下的07-join.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
子查询
要求:
- 查询工资比名为 Ellen 高的员工的名字和工资
- 查询与编号为 141 的员工工种相同,比编号为 143 的员工月薪高的员工名字、工种编号和月薪
- 查询工资最少的员工的名字、工种和月薪
- 查询部门编号和该部门的最低月薪 min_salary,要求部门最低月薪大于 100 号部门的最低月薪
- 返回位置编号是 1400 和 1500 两个部门中的所有员工名字
- 查询其它工种中比 it_prog 工种中任一工资低的员工的员工编号、名字、工种和月薪
- 查询比 it_prog 工种所有工资都高的部门的部门编号和最低月薪
- 查询员工编号最小并且工资最高的员工信息
- 查询 employees 的部门编号和管理者编号在 departments 表中的员工名字,部门编号和管理者编号
- 查询每个部门信息和该部门员工个数
- 查询 90 编号的部门员工人数占公司总人数的比例,带百分号,小数点后保留一位
- 查询部门编号、该部门的平均工资 average_salary 和工资等级,平均工资去掉小数部分
- 查询有员工的部门名称
- 查询和 Eleni 相同部门的员工名字和工资
- 查询比公司平均工资高的员工的员工编号、名字和工资,并按工资升序排序
- 查询各部门中工资比本部门平均工资高的员工的员工编号、名字和工资
- 查询和名字中包含字母 u 的员工在相同部门的员工的员工编号和名字
- 查询在部门 location_id 为 1700 的部门工作的员工的员工编号
- 查询员工名字和工资,这些员工的上司的名字是 Steven
- 查询工资最高的员工的姓名 name,
name = first_name, last_name - 查询工资最低的员工的名字和工资
- 查询平均工资最低的部门信息
- 查询平均工资最低的部门信息和该部门的平均工资
- 查询平均工资最高的 job 信息
- 查询平均工资高于公司平均工资的部门有哪些
- 查询所有管理者的详细信息
- 查询各个部门中最高工资中最低的那个部门的最低工资是多少
- 查询平均月薪最高的部门的管理者的名字、部门编号、邮箱和月薪
- 将上面的 SQL 代码放到
02-sql目录下的08-subquery.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
DDL
要求:
- 使用默认字符集创建 library 数据库
- 查看 DBMS 上的所有数据库,确认 library 是否创建成功
- 查看 library 数据库创建使用的字符集
- 查看 DBMS 默认的字符集设置
- 创建 library2 数据库,使用 utf8mb4 字符集
- 查看 DBMS 上的所有数据库,确认 library2 是否创建成功
- 查看 library2 数据库创建使用的字符集
- 切换到 northwind 数据库
- 查看 northwind 数据库,有哪些表
- 查看当前使用的数据库
- 查看 mysql 数据库有哪些表(不要切换到 mysql 数据库)
- 修改 library 数据库,使用 utf8mb4 字符集
- 删除 library2 数据库
- 在 library 数据库中创建 books 表,字段和数据类型如下:
- id int
- name varchar(20)
- price double,
- author_id int,
- publish_date date
- 查看 books 表的字段和数据类型
- 查看 books 表使用的字符集和存储引擎
- 在 library 数据库中创建 emp2 表,该表拥有 northwind.employees 表的 employee_id, first_name 和 salary 三个字段,以及相应的数据
- 在 library 数据库中创建 emp3 表,该表拥有 northwind.employees 表相同结构,但没有数据
- 查看 emp2 表的字段和数据类型
- 查看 emp2 表的字符集和存储引擎
- 查看 emp2 表中的数据
- 对 emp3 做类似的三项检查
- 在 emp2 表中增加一个新字段 hire_date 类型为 date,新字段为最后一个字段,验证操作是否正确,下面操作类似
- 在 emp2 表中增加一个新字段 phone 类型为 varchar(20),新字段为第一个字段
- 在 emp2 表中增加一个新字段 email 类型为 varchar(20),新字段的前一个字段为 salary
- 修改 emp2 表的 employee_id 字段为 id,验证修改是否正确,下面操作类似
- 修改 emp2 表的 email 字段为 mail,并且数据类型改为 varchar(30)
- 修改 emp2 表的 first_name 字段为 varchar(25)
- 修改 emp2 表的 first_name 字段为 varchar(35),默认值为 abc
- 删除 emp2 表的 mail 字段
- 修改 emp2 表的名称为 emp,验证修改是否成功
- 用另一种方式将 emp 表名改为 emp2,验证修改是否成功
- 删除 emp3 表
- 用 delete 方法删除 emp2 表中的所有数据,并验证 delete 是否支持回滚操作
- 用 truncate 方法删除 emp2 表中的所有数据,并验证 truncate 是否支持回滚操作
- 将上面的 SQL 代码放到
02-sql目录下的09-ddl.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
DML
要求:
- 创建数据库 store,验证数据库是否创建成功
- 创建表 books,表结构如下:
- id int
- name varchar(50)
- authors varchar(100)
- price float
- pubdate year
- category varchar(100)
- num int
- 查看 books 表结构
- 查询 books 表中记录
- books 表中数据如下
- id, name, authors, price, pubdate, category, num
- 1, 看见, 柴静, 39.8, 2013, novel, 13
- 2, 我的天才女友, [意] 埃莱娜·费兰特, 42, 2017, joke, 22
- 3, 局外人, [法] 阿尔贝·加缪, 22, 2010, novel, 0
- 4, 步履不停, [日] 是枝裕和, 36.8, 2017, novel, 30
- 5, 法学导论, [德] 古斯塔夫·拉德布鲁赫, 30, 2001, law, 10
- 6, 本草纲目, 李时珍, 30, 1990, medicine, 40
- 7, 火影忍者, [日] 岸本齐史, 88, 1999, cartoon, 28
- 不指定字段名称,向 books 表插入 id 为 1 的记录
- 指定所有字段名称,向 books 表插入 id 为 2 的记录
- 向 books 表同时插入剩余所有记录
- 将小说类型图书的价格增加 5 元
- 将局外人图书的价格改为 40,并将类别改为 memoir
- 删除库存为 0 的图书
- 查找书名中包含火的图书
- 统计书名中包含火的书的数量和库存总量
- 查找 novel 类型的书,按照价格降序排列
- 查询图书信息,按照库存量降序排列,如果库存量相同的按照 category 升序排列
- 按照 category 分类统计书的数量
- 按照 category 分类统计书的库存量,显示库存量超过 35 本的
- 查询所有图书,每页显示 3 本,显示第二页
- 按照 category 分类统计书的库存量,显示库存量最多的
- 查询作者名称达到 7 个字符的书,不包括里面的空格
- 查询书名和类型,其中 category 值为 novel 显示小说,law 显示法律,medicine 显示医药,cartoon 显示卡通,joke 显示笑话
- 查询书名、库存,其中 num 值超过 30 本的,显示滞销,大于 0 并低于 10 的,显示畅销,为 0 的显示需要无货,其他显示正常
- 统计每一种 category 的库存量,并合计总量
- 统计每一种 category 的数量,并合计总量
- 统计库存量前三名的图书
- 找出最早出版的一本书
- 找出 novel 中价格最高的一本书
- 找出作者名中字数最多的一本书,不含空格
- 将上面的 SQL 代码放到
02-sql目录下的10-dml.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
数据类型
- 将上面的 SQL 代码放到
02-sql目录下的11-data-type.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
约束
要求:
- 创建 cs 数据库,下面操作都在这个数据库中完成
- 创建 tb_null 表添加非空约束
- 表中字段如下:
- id int
- name varchar(15)
- email varchar(25)
- salary decimal(10, 2)
- 要求 id 和 name 两个字段不允许为空
- 检查 tb_null 表结构,确认正确设置非空约束
- 在 tb_null 表中插入正常数据和空数据,测试非空约束的效果
- 在 tb_null 表中更改数据,测试非空约束的效果
- 修改 tb_null 表,给 email 字段添加非空约束,确认非空约束设置成功
- 删除 tb_null 表中 email 字段的非空约束,确认非空约束删除成功
- .
- 创建 tb_unique 表添加唯一值约束
- 表中字段如下:
- id int
- name varchar(15)
- email varchar(25)
- salary decimal(10, 2)
- 要求 id 和 email 两个字段是唯一的
- 要求 id 是列级约束,email 是表级约束
- 检查 tb_unique 表结构,确认正确设置唯一值约束
- 在 tb_unique 表中插入正常数据和重复数据,测试唯一值约束的效果
- 在 tb_unique 表中插入空值数据,测试唯一值约束的效果
- 修改 tb_unique 表,给 name 字段添加唯一值约束,确认唯一值约束设置成功
- 删除 tb_unique 表中 name 字段的唯一值约束,确认唯一值约束删除成功
- .
- 创建 tb_user 表添加复合唯一值约束
- 表中字段如下:
- id int
- name varchar(15)
- password varchar(25)
- 要求 name 和 password 两个字段作为整体是唯一的
- 检查 tb_user 表结构,确认正确设置唯一值约束
- 在 tb_user 表中插入正常数据和重复数据,测试唯一值约束的效果
- 在 tb_user 表中插入空值数据,测试唯一值约束的效果
- .
- 创建 tb_pk1 表添加主键约束
- 表中字段如下:
- id int
- name varchar(15)
- email varchar(25)
- salary decimal(10, 2)
- 要求 id 字段是列级主键约束
- 检查 tb_pk1 表结构,确认正确设置主键约束
- 创建 tb_pk2 表跟 tb_pk1 表结构相同,区别是给 id 字段添加表级主键约束
- 在 tb_pk1 表中插入正常数据、重复数据和空数据,测试主键约束的效果
- 创建 tb_pk3 表添加复合主键约束,tb_pk3 表的字段跟 tb_user 相同,name 和 password 两个字段整体作为主键
- 在 tb_pk3 表中插入正常数据、重复数据和空数据,测试复合主键约束的效果
- 创建 tb_pk4 表,跟 tb_pk1 表结构相同,但不设置主键
- 检查 tb_pk4 表结构
- 修改 tb_pk4 表,给 id 字段添加主键约束,验证主键约束添加成功
- 在 tb_pk4 表,删除主键约束
- 将上面的 SQL 代码放到
02-sql目录下的12-constraint.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
视图
要求:
- 创建数据库 vw,下面操作都在这个数据库中完成
- 创建 emps 表,拥有 northwind.employees 表的所有数据
- 创建 depts 表,拥有 northwind.departments 表的所有数据
- 检查两个表中的数据,确保与源表的数据相同
- 检查 emps 与 northwind.employees 表结构,比较两者的差异
- 创建 v_emp1 视图,包含 emps 表中的员工编号、名字和薪水三个字段
- 检查 v_emp1 视图的所有数据,确保跟 emps 表中的记录数相同
- 创建 v_emp2 视图,包含 emps 表中月薪大于 8000 的员工,其编号(emp_id),名字(name)和薪水
- 检查 v_emp2 视图中的所有数据
- 创建 v_emp_sal 视图,包含 emps 表中的部门编号和该部门的平均工资(avg_sal),不包含部门编号为 null 的数据
- 检查 v_emp_sal 视图的所有数据
- 创建 v_emp_dept 视图,包含 emps 表中的员工编号和部门编号以及 depts 表中的部门名称
- 检查 v_emp_dept 视图的所有数据
- 创建 v_emp4 视图,包含 v_emp1 视图中的员工编号和员工名字两个字段
- 检查 v_emp4 视图的所有数据
- 查看 vw_test 数据库中的表对象和视图对象
- 查看 v_emp1 视图的结构
- 查看 v_emp1 视图的状态信息
- 查看 v_emp1 视图的详细定义信息
- 修改 v_emp1 视图的数据,将编号为 101 的员工,月薪改为 20000
- 检查 v_emp1 视图的数据,确保修改成功
- 检查 emps 表,查看 101 编号的员工薪水
- 修改 emps 表中的数据,将编号为 101 的员工,月薪改为 10000
- 检查 emps 表的数据,确保修改成功
- 检查 v_emp1 表,查看 101 编号的员工薪水
- 删除 v_emp1 视图中的数据,将编号为 101 的员工信息删除
- 检查 v_emp1 视图的数据,确保修改成功
- 检查 emps 表,查看 101 编号的员工信息
- 在 v_emp_sal 视图中,将编号为 30 的部门,平均工资改为 5000,修改是否成功,为什么
- 在 v_emp_sal 视图中,删除编号为 30 的部门信息,修改是否成功,为什么
- 修改 v_emp1 视图,包含工资大于 7000 的员工编号,名字,工资和 email 字段
- 删除 v_emp4 视图,删除前后分别查看 vw_test 库中的所有表和视图,确认删除成功
- 将上面的 SQL 代码放到
02-sql目录下的13-view.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
存储过程和存储函数
要求:
- 创建数据库 pf,下面的操作都在这个数据库完成
- 创建存储过程 all_data,查询 employees 表的所有数据,调用该存储过程,验证其功能是否正确
- 下面创建的存储过程或存储函数都需要调用和验证,不再赘述
- 创建存储过程 avg_salary,查询 employees 表所有员工的平均工资
- 创建存储过程 max_salary,查询 employees 表的最高工资
- 创建存储过程 min_salary,查询 employees 表的最低工资,并将最低工资通过参数 minSalary 输出
- 创建存储过程 get_salary_by_id,查询 employees 表某员工的工资,入口参数是 emp_id 员工编号
- 创建存储过程 get_salary_by_name,查询 employees 表某员工的工资,入口参数是 emp_name 员工名字,出口参数是 salary 该员工的工资
- 创建存储过程 get_mgr_name,查询 employees 表中某员工领导的名字,参数 name 同时作为输入的员工名字和输出的领导名字
- 创建存储函数 avg_salary,返回 employees 表所有员工的平均工资
- 创建存储函数 get_mgr_name,返回 employees 表中某员工名字的领导的名字
- 创建存储函数 get_count_by_dept_id,返回 employees 表某部门编号的部门员工人数
- 查看存储过程 all_data 的代码
- 查看存储函数 get_count_by_dept_id 的代码
- 查看存储过程 all_data 的状态
- 查看存储函数 avg_salary 的状态
- 查看存储过程 avg_salary 的对象信息
- 查看存储函数 avg_salary 的对象信息
- 修改存储过程 avg_salary,添加注释,修改 sql security 为 invoker
- 删除存储过程 get_mgr_name,验证该对象确实删除
- 删除存储函数 avg_salary,验证该对象确实删除
- 将上面的 SQL 代码放到
02-sql目录下的14-procedure-function.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
触发器
要求:
- 做下面的准备工作
- 创建数据库 tg(下面的操作都在这个数据库完成)
- 检查 tg 数据库是否创建成功
- 创建表 tb_tg,包括两个字段:id 字段(int、主键、自增)和 note 字段(varchar(20))
- 创建表 tb_tg_log,包括两个字段:id 字段(int、主键、自增)和 log 字段(varchar(40))
- 创建表 employees,包括四个字段:employee_id, first_name, salary 和 manager_id,数据来自 northwind.employees
- 检查三个表的结构
- 检查 employees 表的数据,确认有 northwind.employees 表对应的 107 条记录
- 创建名为 after_insert 的触发器,在 tb_tg 表插入数据后,向 tb_tg_log 表中插入日志信息
- 日志信息的格式是:
[datetime insert]: note,datetime 代表 insert 发生的当前日期和时间,下同 - 查看该触发器,确认创建成功
- 在 tb_tg 表添加一条日志,内容随意
- 查看 td_tg 和 td_tg_log 表的数据,确认触发器正常工作
- .
- 创建名为 after_delete 的触发器,在 tb_tg 表删除数据后,向 tb_tg_log 表中插入日志信息
- 日志信息的格式是:
[datetime delete]: note - 查看该触发器,确认创建成功
- 在 tb_tg 表删除一条日志
- 查看 td_tg 和 td_tg_log 表的数据,确认触发器正常工作
- .
- 定义触发器 salary_check,在员工表添加新员工前检查其薪资是否大于他领导的薪资
- 如果员工薪资大于其领导薪资,则报 sqlstate 为 45000 的错误
- 查看该触发器,确认创建成功
- 在员工表表添加一条记录,做通过性测试,检查员工表的数据
- 在员工表表添加一条记录,做失效性测试,检查员工表的数据
- 确认这个触发器能正常工作
- .
- 分别用三种方式查看上面创建的某个触发器
- 删除上面创建的三个触发器
- .
- 将上面的 SQL 代码放到
02-sql目录下的16-trigger.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
复合语句
要求:
- 创建数据库 cs,下面的操作都在这个数据库完成
- 创建 employees 表,拥有 northwind.employees 表的所有数据
- .
- raise_salary 1-3 用 if 分支实现
- 创建存储过程 raise_salary1,入口参数:员工编号。如果员工薪资低于 8000 元且工龄超过 5 年,涨薪 500 元,否则不变。
- 确认该存储过程创建成功
- 调用该存储过程并传入员工编号 104
- 检查 104 编号的员工在调用存储过程前后工资的变化,确认存储过程执行是否成功
- .
- 创建存储过程 raise_salary2,入口参数:员工编号。如果员工薪资低于 9000 元且工龄超过 5 年,涨薪 500 元;否则涨薪 100 元。
- 确认该存储过程创建成功
- 调用该存储过程并分别传入员工编号 103 和 104
- 检查 103 和 104 编号的员工在调用存储过程前后工资的变化,确认存储过程执行是否成功
- .
- 创建存储过程 raise_salary3,入口参数:员工编号。如果员工薪资低于 9000 元且工龄超过 5 年,则涨薪到 9000,薪资大于 9000 且低于 10000,并且没有提成的员工,涨薪 500 元;其他涨薪 100 元。
- 确认该存储过程创建成功
- 调用该存储过程并分别传入员工编号 102、103 和 104
- 检查 102、103 和 104 编号的员工在调用存储过程前后工资的变化,确认存储过程执行是否成功
- .
- raise_salary 4-5 用 case 分支实现
- 创建存储过程 raise_salary4,入口参数:员工编号。如果员工薪资低于 9000 元,则涨薪到 9000,薪资大于 9000 且低于 10000,并且没有提成的员工,涨薪 500 元;其他涨薪 100 元。
- 确认该存储过程创建成功
- 调用该存储过程并分别传入员工编号 101、104 和 105
- 检查 101、104 和 105 编号的员工在调用存储过程前后工资的变化,确认存储过程执行是否成功
- .
- 创建存储过程 raise_salary5,入口参数:员工编号。如果员工工龄是 0 年,涨薪 50;如果工龄是 1 年,涨薪 100;如果工龄是 2 年,涨薪 200;如果工龄是 3 年,涨薪 300;如果工龄是 4 年,涨薪 400;其他的涨薪 500。
- 确认该存储过程创建成功
- 调用该存储过程并分别传入员工编号 101、104 和 105
- 检查 101、104 和 105 编号的员工在调用存储过程前后工资的变化,确认存储过程执行是否成功
- .
- 下面的功能分别用 loop、while 和 repeat 实现
- 创建存储函数 factorial,计算 n!,入口参数 n,返回值 n! = 1 × 2 × … × n
- 确认该存储函数创建成功
- 调用该存储函数,确认该存储函数执行是否成功
- .
- 创建存储过程 pyramid,入口参数 n,输出 n 层法老的金字塔,当 n = 3 时,金字塔如下:
*********
- 确认该存储过程创建成功
- 调用该存储过程,确认该存储过程执行是否成功
- .
- 创建存储过程 mult_talbe,输出九九乘法表
- 确认该存储过程创建成功
- 调用该存储过程,确认该存储过程执行是否成功
- .
- 声明存储过程 raise_salary6,给全体员工涨薪,每次涨幅为 10%,直到全公司的平均薪资达到 12000 为止,返回上涨次数。
- 确认该存储过程创建成功
- 调用该存储过程,确认该存储过程执行是否成功
- .
- 创建存储函数 get_count,计算薪资最高员工的工资之和达到 total_salary 的人数
- 调用该存储函数,确认该存储函数执行是否成功
- .
- 将上面的 SQL 代码放到
02-sql目录下的15-compound-statemnet.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
DCL
要求:
- 创建 MySQL 用户,用户名:自己姓名的拼音,密码:123456
- 创建 MySQL 用户,用户名:zhang3@localhost,密码:123456
- 查看创建的用户
- 查看当前登录用户
- 修改用户 zhang3 为 li4,刷新权限
- 用 drop 关键字删除 li4 用户
- 创建 zhang3 用户,用 delete 关键字删除 zhang3 用户,刷新权限
- 用 alter 关键字修改当前用户(root)的密码,重新登录 MySQL
- 用 set 关键字修改当前用户(root)的密码,重新登录 MySQL
- 用 alter 关键字修改自己姓名用户的密码为 ddd
- 用 set 关键字修改自己姓名用户的密码为 123456
- 列出 MySQL 的所有权限
- 授予自己姓名用户 northwind 库所有表的增、删、改、查权限,用自己姓名用户登录 MySQL,查询 northwind
- 授予自己姓名用户所有库所有表的权限,用自己姓名用户名登录 MySQL,建库、查询 northwind
- 查看当前用户的权限
- 查看 root 或自己姓名账户的权限
- 收回自己姓名用户的所有权限,用自己姓名用户登录 MySQL
- 查看 mysql.user 表结构
- 查看 mysql.user 表的所有数据
- 查看 mysql.user 表中 user, host 和 authentication_string(加密的密码) 三列数据
- 查看 mysql.db 表结构和数据
- 查看 mysql.tables_priv 表结构和数据
- 查看 mysql.columns_priv 表结构和数据
- 查看 mysql.procs_priv 表结构和数据
- .
- 将上面的 SQL 代码放到
02-sql目录下的17-dcl.sql文件中 - 提交代码仓库,推送到 bitbucket 远程代码仓库
程序语言访问数据库
要求:
- college 数据库中有 scores 表
- scores 表的结构和数据,参考 scores.xlsx 文件
- 编写 18-setup.sql 脚本完成 college 库的创建,scores 表的创建和 scores 数据的插入
- 编写 18-score.py 脚本,对 scores 表做增、删、改、查操作
- 18-score.py 脚本的功能界面,参考基于文件的数据管理
- .
- 将上面的 SQL 代码放到
02-sql目录 - 提交代码仓库,推送到 bitbucket 远程代码仓库